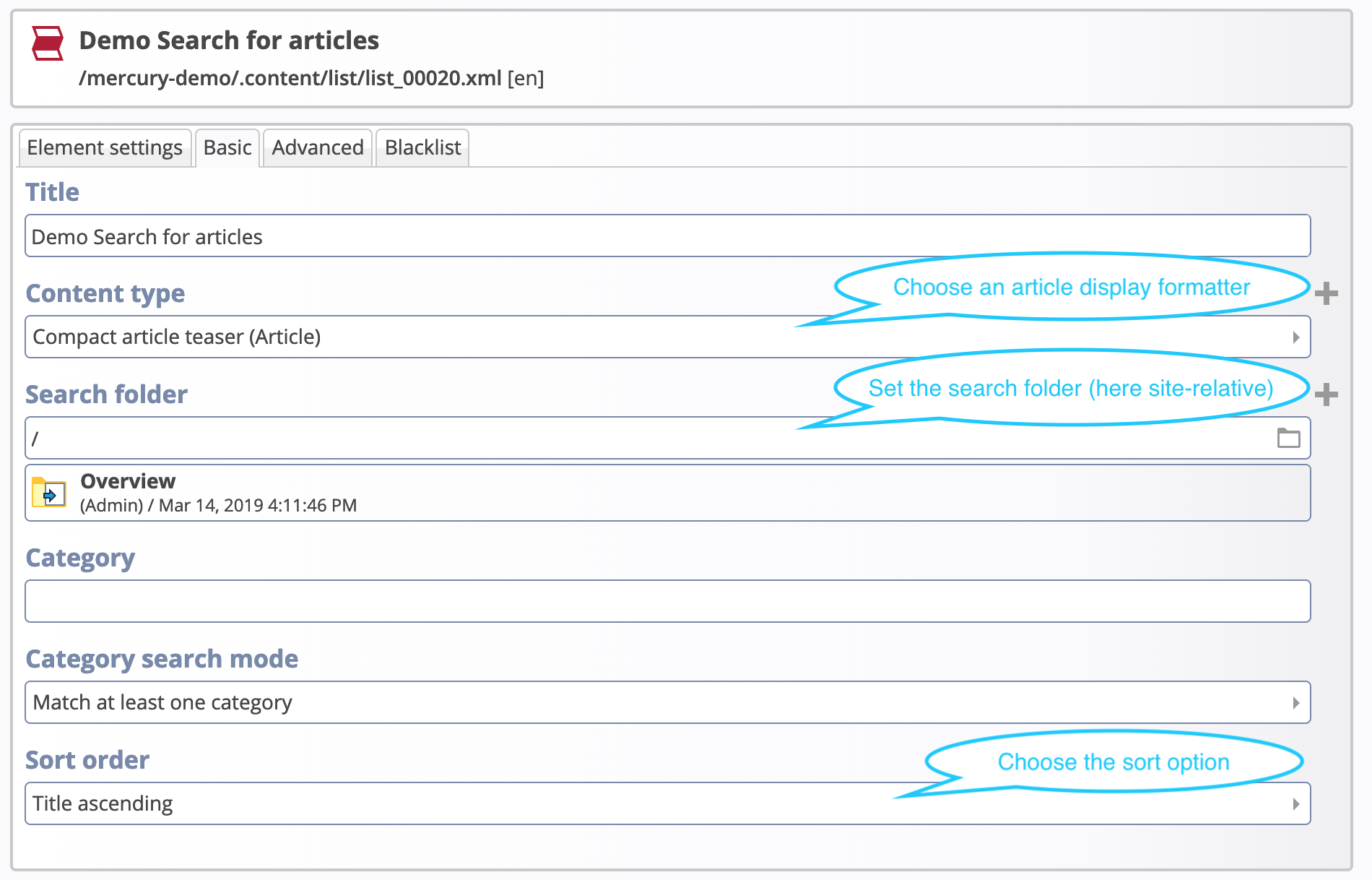
Apache Solr is an enterprise search engine based on Lucene. It can be installed as stand-alone or embedded server and can be queried via a REST API or a special Java API.
Basically, you have to add all the resources you want to search for to a Solr index. Adding a resource is called "indexing" it. To index a resource, you extract the information from it - e.g., its content, its location, its type - and put each of this information in a so called "field" of a "document". Hence, each resource is represented by a document in a Solr index. Each document has various fields - e.g. one called "content" (holding the content), one called "location" (holding the link to the original resource, .... Once you added a document for your resource to a Solr index, you can ask Solr for all documents fullfilling certain conditions (that you specify in the query). For example, you might index some PDF files and ask Solr for up to 10 documents that contain the word "OpenCms". Solr can even rank the result, hence returning a document containing "OpenCms" very often before a document that contains "OpenCms" just once.
Solr has many more advanced features that you have already used to when visiting Google or Amazon:
- Faceted search
- Highlighting
- Range queries
- Sorting
- Spellchecking
- Auto suggestion/completion/correction
- Thesaurus/Synonyms
- ...
So Solr is great to implement a full text search for your website with many advanced features. But of course, it is as well a great choice for very simple searches.